Thurs, August 13th, 9am PDT/12pm EDT/18:00 CEST – Register now!
Hosted by the COVID-19 Data Forum/Stanford Data Science Initiative/R Consortium
COVID-19 is the first pandemic to occur in the age of open data. Public health agencies around the world are releasing case counts to the public, and scientists are providing analyses and forecasts in real-time. However, the content of this data has so far been limited to simple metrics like cases, deaths, and hospitalizations at coarse geographic and demographic scales. To drive the next phase of COVID-19, scientists need access to higher-dimensional patient-level data, so we can understand how the virus causes disease, why are some more at risk than others, when and how is transmission occurring, what therapeutics are more likely to work, and what healthcare resources are being used. But sharing such data brings up tremendous challenges in terms of patient privacy and data standardization. The COVID-19 Data Forum, a collaboration between Stanford University and the R Consortium, is hosting the event “Beyond case counts: Making COVID-19 clinical data available and useful” to push the conversation forward on these issues. The event will include talks by representatives from international collaborative teams who are working to collect and share detailed clinical and biological data from individuals with COVID-19. The event will be open to the public, and is part of a continuing series focusing on data-related aspects of the scientific response to the pandemic.
Speakers include:
Jenna Reps, Observational Health Data Sciences & Informatics (OHDSI) Consortium /Janssen R&D
Andrea Ganna, COVID-19 Host Genetics Initiative/Harvard Medical School/Finland Institute for Molecular Medicine
Ken Massey, EndPandemic National Data Consortium/Saama Technologies
Ryan Tibshirani, DELPHI epidemic forecasting group/Dept of Statistics, Carnegie Mellon University
On June 19th, 2020, we filmed a video for useR!2020 showcasing the communities and organizations we are involved in that are for Latin Americans or have Latin American participants. In this blog post, we wanted to highlight these initiatives and remind everyone that we are more than happy to help you launch similar initiatives in your local communities.
LatinR: LatinR is a trilingual international conference on the use of R in research and development across Latin America. Since launching in 2018, our annual meetings have been a starting point for new packages, local user groups, reading clubs, R-Ladies chapters, translations, and other initiatives in the region.
ConectaR: ConectaR 2019 took place during January 24-26, 2019 at the University of Costa Rica, in San José, Costa Rica. It was the first event in Central America endorsed by The R Foundation, and it was held completely in Spanish. You can find more information here.
satRday: SatRday is a conference about R and its applications, that happens all over the world, and it is organized by the local community. Two satRdays events happened in Latin America: in Santiago – Chile and São Paulo – Brazil. If you want to organize a satRday anywhere in Latin America, please get it touch so we can help each other!
R-Ladies: R-Ladies is a global organisation that promotes gender diversity in the R community. It has 123 active chapters in 51 countries around the world, of which 49 are found across 10 Latin American countries. Some Latin Americans are part of the R-Ladies Global Team, including its leadership. COVID-19 has not stopped us, instead, we have migrated online and fostered alliances among different chapters. All in an effort to give gender minorities in the R community the opportunity to learn R in a safe and supportive environment. Join us!
rOpenSci: R for open science, rOpenSci, provides free technical review of R packages to improve the quality of open source software in order to maximize readability, usability, usefulness, and minimize redundancy. Their peer-review process will soon be translated to Spanish and you can get involved!
RUGs: there are several R User Groups in Latin America, some of which are officially sponsored by the R Consortium. We believe that creating a welcoming space is crucial for keeping the ideas flowing, which allows for meaningful networking and, consequently, the development of new projects. We can help you start your own group!
R4DS in Spanish + datos package: the resources to learn R in English are many, awesome, online, and free. But in Latin America few people can afford to learn English, and the resources in Spanish are few. To help solve this problem, we community-translated to Spanish the “R for Data Science” book and developed a package with the translation of all the datasets used in it: datos. The workflow to contribute to the package was designed to engage first-time contributors, and is now guiding the development of a new version in Portuguese that will be released in the next few months.
#DatosDeMiércoles + #30díasdegráficos: The @R4DS_es Twitter account was created as a way to share projects like the R4DS translation and to developed initiatives to foster the Spanish-speaking R community, like #datosdemieRcoles, the Latin American cousin of #TidyTuesday. The idea is not only to use datasets that are in Spanish, but also datasets that are relevant for our Region. This initiative has been complemented with the 30 days plot challenge #30díasdegráficos. If you want to participate proposing a dataset for #datodemiéRcoles, please visit our github repo.
The Carpentries: The Carpentries builds global capacity in essential data and computational skills for conducting efficient, open, and reproducible research. Building a sustainable and active community in Latin America includes several initiatives: lesson translations, instructor training, workshop coordination, and fundraising. Get in touch with us through the mailing list and the carpentries-es channel at the Carpentries Slack workspace.
ReproHack: ReproHack is a growing community for researchers that are fighting the reproducibility crisis by sharing their experiences across disciplines. It is focused on organizing hackathons where participants attempt to reproduce published research from a list of proposed papers with public code and data. We are planning the first ReproHack in Spanish for October 2020 and you can get in touch with us through Twitter.
AI Inclusive: AI Inclusive is an organization that promotes diversity in the AI Community. We want to bring awareness around Artificial Intelligence issues and empower the community so they can enter in the AI field, a field that is not diverse at all. In December 2019, we had our launch events in Rio de Janeiro, Brazil and San Francisco, California. Follow us and join us!
Data Latam: in May 2016 we started with the first Data Latam podcast, aimed at offering an easy entry point, in Spanish, to those interested in data science. We always ask our interviewees: “How did you get where you are?”, and the diversity of stories has been enormous. Today Data Latam is a Latin American community of professionals and academics, who apply data science in their day to day work and we invite you to participate!
What happens in the R Community doesn’t stay in the R Community. All the good practices of inclusive and diverse communities learned in several of the initiatives presented before, generate strong work teams within and beyond the R community. There is still a lot to be done, but what we’ve already achieved is very encouraging and provides a solid foundation for the future.
These initiatives are sustained by many people making a great, mostly volunteer, effort behind the scenes. Some of the challenges that the communities face are translated into multiple positives, sustained, and a lot of invisible hard work. Some of them are: finding international funding due to limited local options, translating content, joining forces across organizations, organizing regional conferences, and becoming active developers of the technology.
The Latin American R community is growing fast and so does the responsibility to make this growth solid and safe. Some of the future work that we, as community builders, look forward to fulfilling are: consolidating regional conferences with support of international sponsors; acquiring funding to sustain translations; amplifying the voices of regional minorities; importing educational material and work opportunities; connecting expats with their local communities; helping other groups such as RUGs and RLadies; connecting with other initiatives such as R-Forwards, Africa-R, MiR, among others; Increase our and other minorities representation in the R Core Team, the R Foundation, and the R Consortium.
Thank you! Please watch our useR! 2020 video on YouTube.
R Consortium interview with Dr. Heather Turner, Chair of Forwards, the R Foundation taskforce for underrepresented groups in the R Community
In January, R Consortium posted about a crowd-funding campaign for Building the R Community in Southern Africa. In February, they successfully raised £2,700 with 44 supporters in 28 days. Fantastic!
We wanted to get a mid-year update and also more details on R communities in Southern Africa so we spoke with Dr. Heather Turner, chair of Forwards, a R Foundation taskforce for underrepresented groups. Dr. Turner is a Honorary Research Fellow of the Statistics Department at the University of Warwick, UK. She brings nearly 20 years of experience with R. Recently, Dr. Turner raised money to fund several workshops and talks in order to develop the R community in South Africa.
———————–
What were some of the interesting ways R is being used in Southern Africa?
R is being used in academia, government organisations, non-profits and businesses. It is perhaps not as common as SPSS or Python, but an enthusiastic community is growing. I was able to discover where R was being used through the people I met and the companies that hosted or supported some of the events. However, the Johannesburg satRday was my main opportunity to see how R was being used. Several of the talks had an African focus, such as Anelda van der Walt’s talk on the afrimapr project making it easier to map data by administrative regions:
Kirsty Lee Garcon’s talk on mapping African genomic data with the sf package:
And Astrid Radermacher’s talk on unravelling the mysteries of resurrection plants (specifically, a native African one) using various R packages:
Among the general R talks, I particularly enjoyed Diana Pholo’s talk “From Pythonista to Rtist”, which gave practical advice:
Drikus du Toit’s talk on SHAP: Interpreting ML Models with IML (), which looked at modelling whether a person would default on a loan.
And Roberto Bennetto’s talk on exploring the Corona outbreak with R, which, back in March 7, was one the first looks I’d had at data from the pandemic.
How has R literacy helped to empower women in areas like Johannesburg or Kampala where satRday events have been hosted?
Learning R is one way that women can unlock the power of data science. This can be directly applied to issues of gender equality as Caroline Akoth demonstrated through her talk on the work of Women in GIS, Kenya, at satRday Johannesburg.
Alternatively, it can give women the opportunity to lead the way to more open, reproducible practices, as satRday Kampala keynote Shelmith Kariuki recently demonstrated by extracting the Kenya Population and Housing Census results from PDF files and publishing them as tidy datasets in her rKenyaCensus package: https://github.com/Shelmith-Kariuki/rKenyaCensus
In general, expertise in R is a powerful skill that can help women to progress in their careers and make a difference in the world.
The satRday events play an important role in inspiring women to pursue data science and to take on responsibilities in the R community. After the satRday in Abidjan, three women joined the board of the Abidjan R Users group and they have already been active in planning and leading R training. The first satRdays in Africa were held in Cape Town and the organizing team made a concerted effort to have a strong representation of women in the program, inviting only women keynotes and proactively encouraging women to submit abstracts. This commitment to the inclusion of women has continued with the subsequent South African satRdays and has been very effective. It can be motivating for women in the audience to see women on stage; after the first Cape Town satRday, Theoni Photopoulou was inspired to start an R-Ladies group. She was joined by Megan Beckett and they co-founded R-Ladies Cape Town. Since then, there has been a symbiotic relationship between R-Ladies and satRdays in South Africa, where one helps to promote the other and both help to strengthen women’s R literacy and social networks.
The community and social network are just as important as R literacy. R-Ladies groups such as those in Cape Town and Johannesburg provide a particularly supportive space for women and gender minorities to learn R. But satRdays and regular R User Groups also help to connect women to R users outside their university or workplace. For some women, these connections have lead directly to new jobs requiring (more) R expertise. More generally, women can tap into their network to help them navigate interviews, negotiate competitive salaries and handle both technical and inter-personal issues that come up in their work.
As women learn more about R and are supported by the community, they become confident in themselves, impacting the wider community. For example, Astrid Radermacher, a co-organizer of R-Ladies Cape Town, has started to run free R classes at her institution and it is mostly women that attend. Shakirah Nakalungi, a co-organizer of the satRday in Kampala, is an ambassador for Zindi, a Kaggle-like platform focused on solving Africa’s most pressing problems. R-Ladies Johannesburg has partnered with ‘Women in Big Data’, ‘Coding Mamas’, ‘WiMLDS’ and other groups, widening their impact. In this way, women empowered by learning R pay it forward within the R community and beyond.
Your data (https://forwards.github.io/data/) shows that the average age for packet authors was approximately 39 years old. Has it been your experience that young adults find R to be daunting?
I don’t think that young adults find R to be daunting any more than older adults. The data you refer to is quite old now (from 2010); back then it was still unusual for R to be taught at undergraduate level. So most people would learn R during their postgraduate studies or later in life and it would take a few years to get to the stage where they might write a package, hence most package authors were over 25. I would expect the distribution to have shifted a little to younger ages these days, however the average age would still be relatively old, as thankfully writing an R package is not a fatal event and us older maintainers live on!
What has been the most gratifying part of putting on events like R-Ladies or satRday? The most frustrating?
The most gratifying part is people enjoying the event. It’s great when you get positive feedback or people post something online saying how they learnt something that they’re keen to try out or how they felt welcomed and supported by the folks at the event. The frustrating part is people wanting a lot more from you when you’ve volunteered to do a particular thing. On the one hand, it’s often something I would want to do and would be good at. On the other, the small asks add up and can become too much, so something has to give. This is challenging to me as a community organizer, it’s easiest to say “X is good at that, let’s ask them”, but we need to be respectful of people’s time and keep looking to bring new people in to share the work.
Do you see R being used more in Africa over the coming 3-5 years?
Yes I do. My impression is that R is not widely taught in universities across Africa, but initiatives like eR-Biostat are helping to change that. Often students will self-learn R, or learn through a one-off workshop perhaps by a visiting lecturer or run by the Carpentries. R users that are trying to encourage others to use or learn R can face a couple of frustrating attitudes. One is that R is only used in universities and is not useful in other sectors. Another is that R is something to be feared because increased automation may make people’s jobs redundant. Such attitudes are why I think it is critical to build the community around R, with R user groups, satRdays and online networks, so that people can see the variety of ways R is used and see that increasing data science literacy can lead to more interesting, skilled work. The R community is growing in Africa and I think this in turn will encourage wider adoption of R in the next few years.
This post was contributed by Peter Li. Thank you, Peter!
packageRank is an R package that helps put package download counts into context. It does so via two functions. The first, cranDownloads(), extends cranlogs::cran_downloads() by adding a plot() method and a more user-friendly interface. The second, packageRank(), uses rank percentiles, a nonparametric statistic that tells you the percentage of packages with fewer downloads, to help you see how your package is doing compared to all other CRAN packages.
In this post, I’ll do two things. First, I’ll give an overview of the package’s core features and functions – a more detailed description of the package can be found in the README in the project’s GitHub repository. Second, I’ll discuss a systematic positive bias that inflates download counts.
Two notes. First, in this post I’ll be referring to active and inactive packages. The former are packages that are still being developed and appear in the CRAN repository. The latter are “retired” packages that are stored in the CRAN Archive along with past versions of active packages. Second, if you want to follow along (i.e., copy and paste code), you’ll need to install packageRank (ver. 0.3.5) from CRAN or GitHub:
cranDownloads() uses all the same arguments as cranlogs::cran_downloads():
cranlogs::cran_downloads(packages = "HistData")
date count package
1 2020-05-01 338 HistData
cranDownloads(packages = "HistData")
date count package
1 2020-05-01 338 HistData
The only difference is that `cranDownloads()` adds four features:
Check package names
cranDownloads(packages = "GGplot2")
## Error in cranDownloads(packages = "GGplot2") :
## GGplot2: misspelled or not on CRAN.
cranDownloads(packages = "ggplot2")
date count package
1 2020-05-01 56357 ggplot2
This also works for inactive packages in the [Archive](https://cran.r-project.org/src/contrib/Archive):
cranDownloads(packages = "vr")
## Error in cranDownloads(packages = "vr") :
## vr: misspelled or not on CRAN/Archive.
cranDownloads(packages = "VR")
date count package
1 2020-05-01 11 VR
Two additional date formats
With cranlogs::cran_downloads(), you can specify a time frame using the from and to arguments. The downside of this is that you must use the “yyyy-mm-dd” format. For convenience’s sake, cranDownloads() also allows you to use “yyyy-mm” or “yyyy” (yyyy also works).
“yyyy-mm”
Let’s say you want the download counts for HistData for February 2020. With cranlogs::cran_downloads(), you’d have to type out the whole date and remember that 2020 was a leap year:
cranlogs::cran_downloads(packages = "HistData", from = "2020-02-01",
to = "2020-02-29")
With cranDownloads(), you can just specify the year and month:
cranDownloads(packages = "HistData", from = "2020-02", to = "2020-02")
“yyyy”
Let’s say you want the year-to-date counts for rstan. With cranlogs::cran_downloads(), you’d type something like:
cranlogs::cran_downloads(packages = "rstan", from = "2020-01-01",
to = Sys.Date() - 1)
With cranDownloads(), you can just type:
cranDownloads(packages = "rstan", from = "2020")
Check dates
cranDownloads() tries to validate dates:
cranDownloads(packages = "HistData", from = "2019-01-15",
to = "2019-01-35")
## Error in resolveDate(to, type = "to") : Not a valid date.
Visualization
cranDownloads() makes visualization easy. Just use plot():
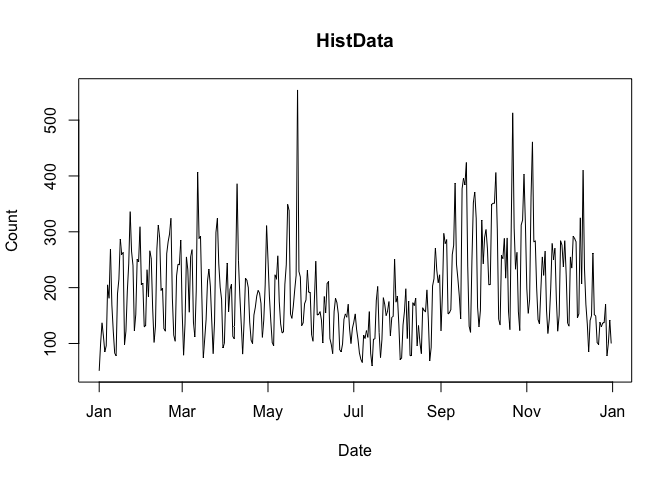
plot(cranDownloads(packages = "HistData", from = "2019", to = "2019"))
Figure 1 Visualize cranDownloads() for A Single Package
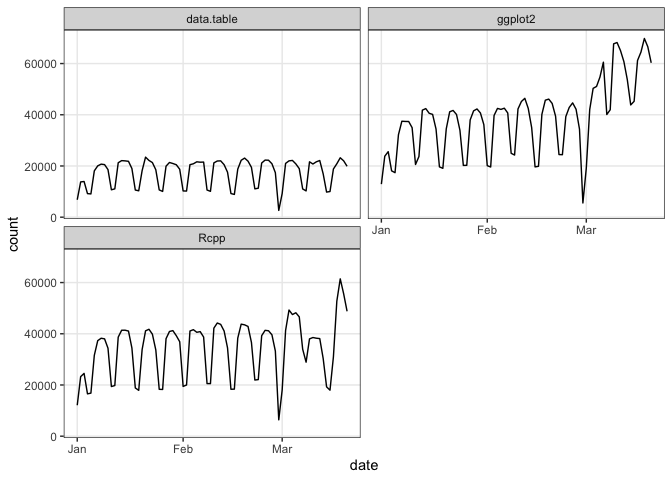
If you pass a vector of package names, plot() will use ggplot2 facets:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"))
Figure 2 Visualize cranDownloads() for Multiple Packages
If you want to plot those data in a single frame, use `multi.plot = TRUE`:
plot(cranDownloads(packages = c("ggplot2", "data.table", "Rcpp"),
from = "2020", to = "2020-03-20"), multi.plot = TRUE)
For more plotting options, see the README on GitHub and the plot.cranDownloads() documentation.
packageRank()
packageRank began as a collection of functions I wrote to gauge interest in my cholera package. After looking at the data for this and other packages, the “compared to what?” question quickly came to mind.
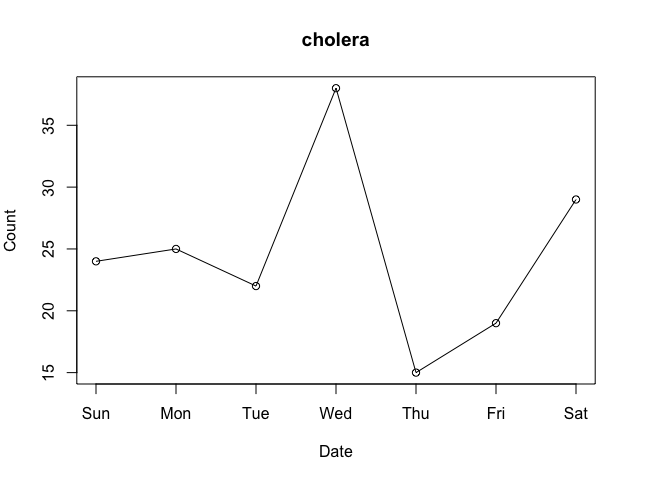
Consider the data for the first week of March 2020:
plot(cranDownloads(packages = "cholera", from = "2020-03-01",
to = "2020-03-07"))
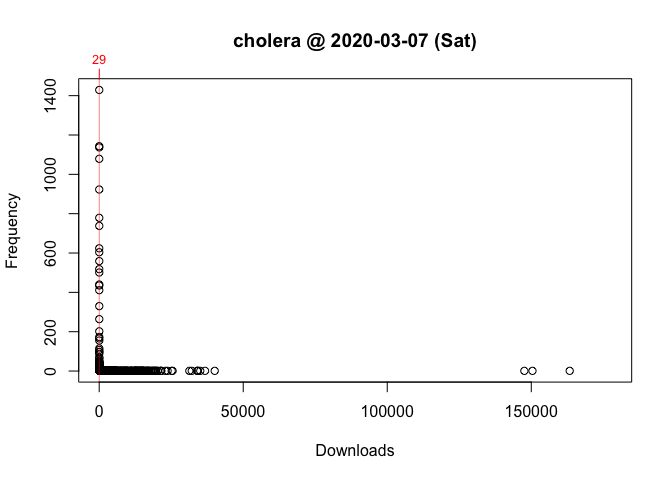
Figure 3 Package Downloads for ‘cholera’ March 1-7, 2020
Do Wednesday and Saturday reflect surges of interest in the package or surges of traffic to CRAN? To put it differently, how can we know if a given download count is typical or unusual?
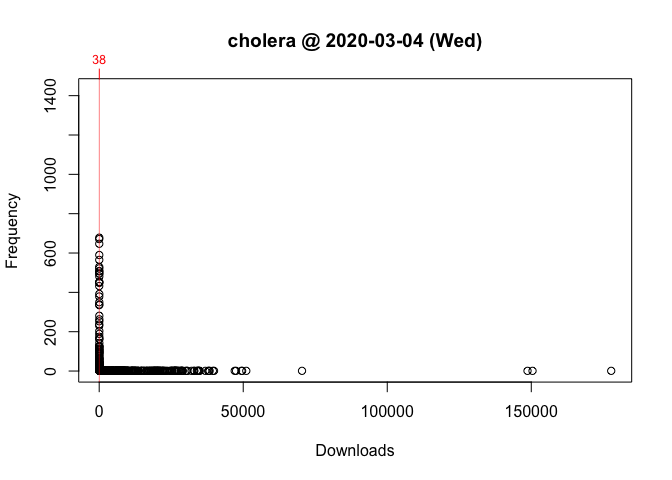
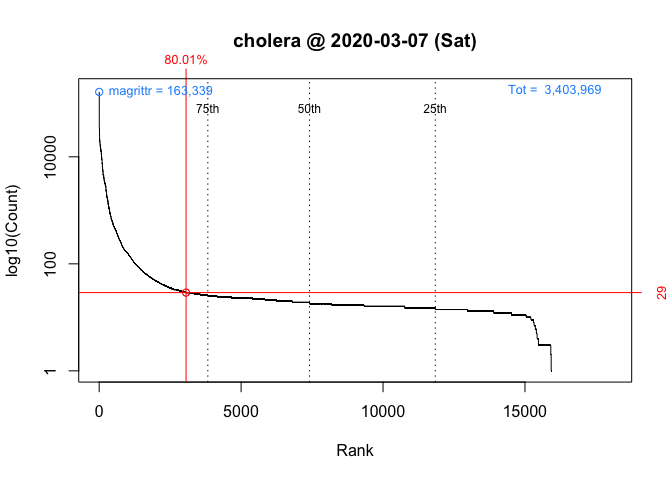
One way to answer these questions is to locate your package in the frequency distribution of download counts. Below are the distributions for Wednesday and Saturday with the location of cholera highlighted:
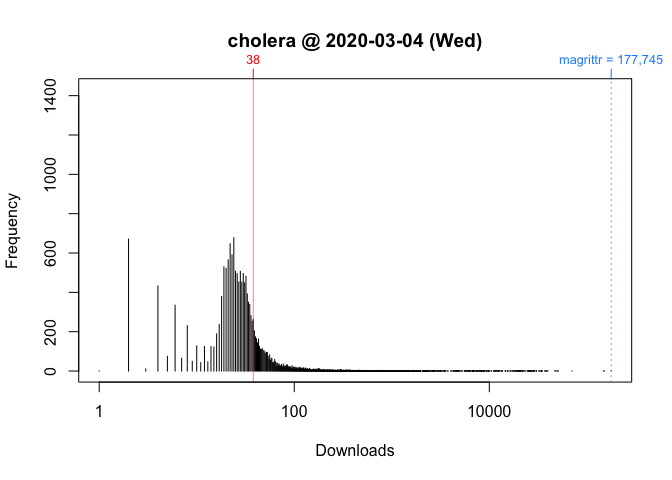
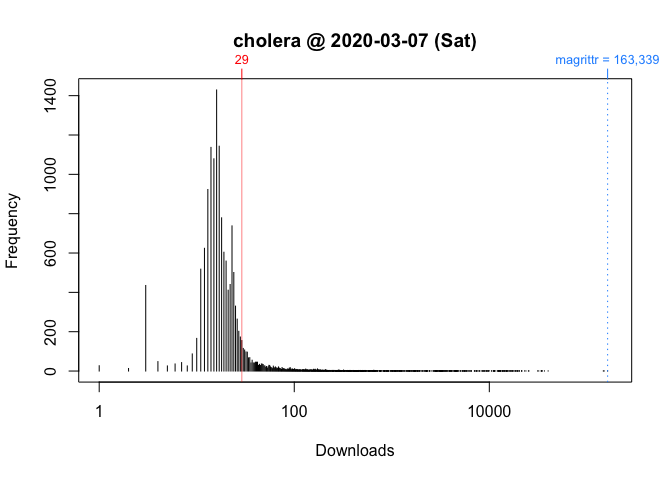
Figure 4 Frequency Distribution of Package Downloads for Wednesday, March 4, 2020Figure 5 Frequency Distribution of Package Downloads for Saturday, March 7, 2020
As you can see, the frequency distribution of package downloads typically has a heavily skewed, exponential shape. On the Wednesday, the most “popular” package had 177,745 downloads while the least “popular” package(s) had just one. This is why the left side of the distribution, where packages with fewer downloads are located, looks like a vertical line.
To see what’s going on, I take the log of download counts (x-axis) and redraw the graph. In these plots, the location of a vertical segment along the x-axis represents a download count and the height of a vertical segment represents the frequency of a download count:
plot(packageDistribution(package = "cholera", date = "2020-03-04"))
Figure 6 Frequency Distribution of Package Downloads for Wednesday, March 4, 2020 with Logarithm of Download Counts
plot(packageDistribution(package = "cholera", date = "2020-03-07"), memoization = FALSE)
Figure 7 Frequency Distribution of Package Downloads for Saturday, March 7, 2020 with Logarithm of Download Counts
While these plots give us a better picture of where cholera is located, comparisons between Wednesday and Saturday are impressionistic at best: all we can confidently say is that the download counts for both days were greater than its respective mode.
To make interpretation and comparison easier, I use the rank percentile of a download count in place of the nominal download count. This rank percentile is a nonparametric statistic tells you the percentage of packages with fewer downloads. In other words, it gives you the location of your package relative to the location of all other packages in the distribution. Moreover, by rescaling download counts to lie on the bounded interval between 0 and 100, rank percentiles make it easier to compare packages both within and across distributions.
For example, we can compare Wednesday (“2020-03-04”) to Saturday (“2020-03-07”):
date packages downloads rank percentile
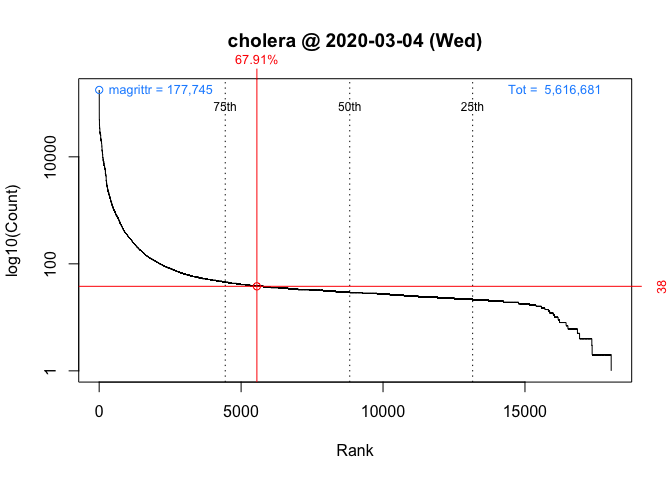
1 2020-03-04 cholera 38 5,556 of 18,038 67.9
packageRank(package = "cholera", date = "2020-03-04", size.filter = FALSE)
On Wednesday, we can see that cholera had 38 downloads, came in 5,556th place out of the 18,038 unique packages downloaded, and earned a spot in the 68th percentile.
date packages downloads rank percentile
1 2020-03-07 cholera 29 3,061 of 15,950 80
packageRank(package = "cholera", date = "2020-03-07", size.filter = FALSE)
On Saturday, we can see that cholera had 29 downloads, came in 3,061st place out of the 15,950 unique packages downloaded, and earned a spot in the 80th percentile.
So contrary to what the nominal counts tell us, one could say that the interest in cholera was actually greater on Saturday than on Wednesday.
Computing rank percentiles
To compute rank percentiles, I do the following. For each package, I tabulate the number of downloads and then compute the percentage of packages with fewer downloads. Here are the details using cholera from Wednesday as an example:
plot(packageRank(packages = "cholera", date = "2020-03-04"))
Figure 8 Rank Frequency Distribution of Package Downloads for Wednesday, March 4, 2020
plot(packageRank(packages = "cholera", date = "2020-03-07"))
Figure 9 Rank Frequency Distribution of Package Downloads for Saturday, March 7, 2020
These graphs, customized to be on the same scale, plot the rank order of packages’ download counts (x-axis) against the logarithm of those counts (y-axis). It then highlights a package’s position in the distribution along with its rank percentile and download count (in red). In the background, the 75th, 50th and 25th percentiles are plotted as dotted vertical lines; the package with the most downloads, which in both cases is magrittr (in blue, top left); and the total number of downloads, 5,561,681 and 3,403,969 respectively (in blue, top right).
Computational limitations
Unlike cranlogs::cran_download(), which benefits from server-side support (i.e., download counts are “pre-computed”), packageRank() must first download the log file (upwards of 50 MB file) from the internet and then compute the rank percentiles of download counts for all observed packages (typically 15,000+ unique packages and 6 million log entries). The downloading is the real bottleneck (the computation of rank percentiles takes less than a second). This, however, is somewhat mitigated by caching the file using the memoise package.
Analytical limitations
Because of the computational limitations, anything beyond a one-day, cross-sectional comparison is “expensive”. You need to download all the desired log files (each ~50 MB). If you want to compare ranks for a week, you have to download 7 log files. If you want to compare ranks for a month, you have to download 30 odd log files.
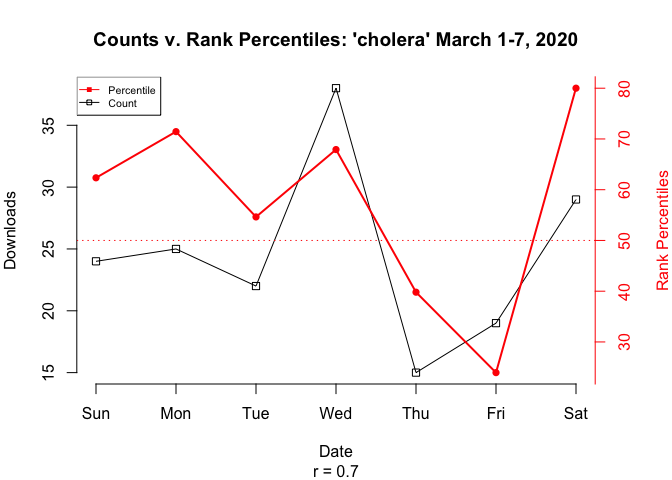
Nevertheless, as a proof-of-concept of the potential value of computing rank percentiles over multiple time frames, the plot below compares nominal download counts with rank percentiles of cholera for the first week in March. Note that, to the chagrin of some, two independently scaled y-variables are plotted on the same graph (black for counts on the left axis, red for rank percentiles on the right).
Figure 10 Comparison of Package Download Counts and Rank Percentiles
Note that while the correlation between counts and rank percentiles is high in this example (r = 0.7), it’s not necessarily representative of the general relationship between counts and rank percentiles.
Conceptual limitations
Above, I argued that one of the virtues of the rank percentile is that it allows you to locate your package’s position relative to that of all other packages. However, one might wonder whether we may be comparing apple to oranges: just how fair or meaningful it is to compare a package like curl, an important infrastructure tool, to a package like cholera, an applied, niche application. While I believe that comparing fruit against fruit (packages against packages) can be interesting and insightful (e.g., the numerical and visual comparisons of Wednesday and Saturday), I do acknowledge that not all fruit are created equal.
This is, in fact, one of tasks I had in mind for packageRank. I wanted to create indices (e.g., Dow Jones, NASDAQ) that use download activity as a way to assess the state and health of R and its ecosystem(s). By that I mean I’d not only look at packages as a single collective entity but also as individual communities or components (i.e., the various CRAN Task Views, tidyverse, developers, end-users, etc.). To do the latter, my hope was to segment or classify packages into separate groups based on size and domain, each with its own individual index (just like various stock market indices). This effort, along with another to control for the effect of package dependencies (see below), are now on the back burner. The reason why is that I’d argue that we first need to address an inflationary bias that affects these data.
Inflationary Bias of Download Counts
Download counts are a popular way for developers to signal a package’s importance or quality, witness the frequent use of badges that advertise those numbers on repositories. To get those counts, cranlogs, which both adjustedcranlogs and packageRank among others rely on, computes the number of entries in RStudio’s download logs for a given package.
Putting aside the possibility that the logs themselves may not be representative of of R users in general1, this strategy of would be perfectly sensible. Unfortunately, three objections can be made against the assumed equivalence of download counts and the number of log entries.
The first is that package updates inflate download counts. Based on my reading of the source code and documentation, the removal of downloads due to these updates is what motivates the adjustedcranlogs package.2 However, why updates require removal, the “adjustment” is either downward or zero, is not obvious. Both package updates (existing users) and new installations (new users) would be of interest to developers (arguably both reflect interest in a package). For this reason, I’m not entirely convinced that package updates are a source of “inflation” for download counts.
The second is that package dependencies inflate download counts. The problem, in a nutshell, is that when a user chooses to download a package, they do not choose to download all the supporting, upstream packages (i.e., package dependencies) that are downloaded along with the chosen package. To me, this is the elephant-in-the-room of download count inflation (and one reason why cranlogs::cran_top_downloads() returns the usual suspects). This was one of the problems I was hoping to tackle with packageRank. What stopped me was the discovery of the next objection, which will be the focus of the rest of this post.
The third is that “invalid” log entries inflate download counts. I’ve found two “invalid” types: 1) downloads that are “too small” and 2) an overrepresentation of past versions. Downloads that are “too small” are, apparently, a software artifact. The overrepresentation of prior versions is a consequence of what appears to be efforts to mirror or download CRAN in its entirety. These efforts makes both “invalid” log entries particularly problematic. Numerically, they undermine our strategy of computing package downloads by counting logs entries. Conceptually, they lead us to overestimate the amount of interest in a package.
The inflationary effect of “invalid” log entries is variable. First, the greater a package’s “true” popularity (i.e., the number of “real” downloads), the lower the bias: essentially, the bias gets diluted as “real” downloads increase. Second, the greater the number of prior versions, the greater the bias: when all of CRAN is being downloaded, more versions mean more package downloads. Fortunately, we can minimize the bias by filtering out “small” downloads, and by filtering out or discounting prior versions.
Download logs
To understand this bias, you should look at actual download logs. You can access RStudio’s logs directly or by using packageRank::packageLog(). Below is the log for cholera for February 2, 2020:
packageLog(package = "cholera", date = "2020-02-02")
date time size package version country ip_id
1 2020-02-02 03:25:16 4156216 cholera 0.7.0 US 10411
2 2020-02-02 04:24:41 4165122 cholera 0.7.0 CO 4144
3 2020-02-02 06:28:18 4165122 cholera 0.7.0 US 758
4 2020-02-02 07:57:22 4292917 cholera 0.7.0 ET 3242
5 2020-02-02 10:19:17 4147305 cholera 0.7.0 US 1047
6 2020-02-02 10:19:17 34821 cholera 0.7.0 US 1047
7 2020-02-02 10:19:17 539 cholera 0.7.0 US 1047
8 2020-02-02 10:55:22 539 cholera 0.2.1 US 1047
9 2020-02-02 10:55:22 3510325 cholera 0.2.1 US 1047
10 2020-02-02 10:55:22 65571 cholera 0.2.1 US 1047
11 2020-02-02 11:25:30 4151442 cholera 0.7.0 US 1047
12 2020-02-02 11:25:30 539 cholera 0.7.0 US 1047
13 2020-02-02 11:25:30 14701 cholera 0.7.0 US 1047
14 2020-02-02 14:23:57 4165122 cholera 0.7.0 <NA> 6
15 2020-02-02 14:51:10 4298412 cholera 0.7.0 US 2
16 2020-02-02 17:27:40 4297845 cholera 0.7.0 US 2
17 2020-02-02 18:44:10 4298744 cholera 0.7.0 US 2
18 2020-02-02 23:32:13 13247 cholera 0.6.0 GB 20
“Small” downloads
Entries 5 through 7 form the log above illustrate “small” downloads:
date time size package version country ip_id
5 2020-02-02 10:19:17 4147305 cholera 0.7.0 US 1047
6 2020-02-02 10:19:17 34821 cholera 0.7.0 US 1047
7 2020-02-02 10:19:17 539 cholera 0.7.0 US 1047
Notice the differences in size: 4.1 MB, 35 kB and 539 B. On CRAN, the source and binary files of cholera are 4.0 and 4.1 MB *.tar.gz files. With “small” downloads, I’d argue that we end up over-counting the number of actual downloads.
While I’m unsure about the kB-sized entry (they seem to increasing in frequency so insights are welcome!), my current understanding is that ~500 B downloads are HTTP HEAD requests from lftp. The earliest example I’ve found goes back to “2012-10-17” (RStudio’s download logs only go back to “2012-10-01”.). I’ve also noticed that, unlike the above example, “small” downloads aren’t always paired with “complete” downloads.
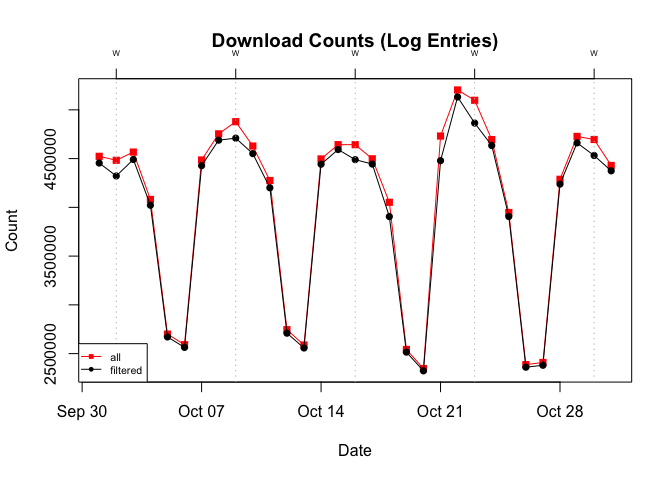
To get a sense of their frequency, I look back to October 2019 and focus on ~500 B downloads. In aggregate, these downloads account for approximately 2% of the total. While this seems modest (if 2.5 million downloads could be modest),3 I’d argue that there’s actually something lurking underneath. A closer look reveals that the difference between the total and filtered (without ~500 B entries) counts is greatest on the five Wednesdays.
Figure 11 Total Package Downloads from CRAN With and Without ~500 B Downloads: October 2019
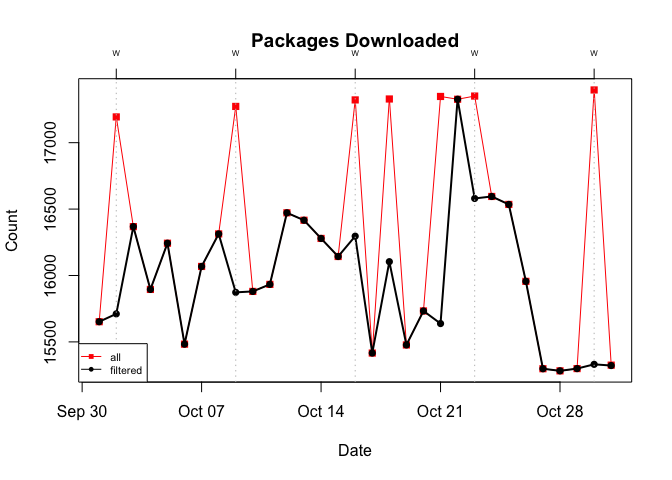
To see what’s going on, I switch the unit of observation from download counts to the number of unique packages:
Figure 12 Total Number of Unique Packages Downloaded from CRAN With and Without ~500 B Downloads: October 2019
Doing so, we see that on Wednesdays (+3 additional days) the total number of unique packages downloaded tops 17,000. This is significant because it exceeds the 15,000+ active packages on CRAN (go here for the latest count). The only way to hit 17,000+ would be to include some, if not all, of the 2,000+ inactive packages. Based on this, I’d say that on those peak days virtually, if not literally, all CRAN packages (both active and inactive) were downloaded.4
Past versions
This actually understates what’s going on. It’s not just that all packages are being downloaded but that all versions of all packages are being regularly and repeatedly download. It’s these efforts, rather than downloads done for reasons of compatibility, research, or reproducibility (including the use of Docker) that lead me to argue that there’s an overrepresentation of prior versions.
As an example, see the first eight entries for cholera from the October 22, 2019 log:
packageLog(packages = "cholera", date = "2019-10-22")[1:8, ]
These eight entries record the download of eight different versions of cholera. A little digging with packageRank::packageHistory() reveals that the eight observed versions represent all the versions available on that day:
Showing that all versions of all packages are being downloaded is not as easy as showing the effect of “small” downloads. For this post, I’ll rely on a random sample of 100 active and 100 inactive packages.
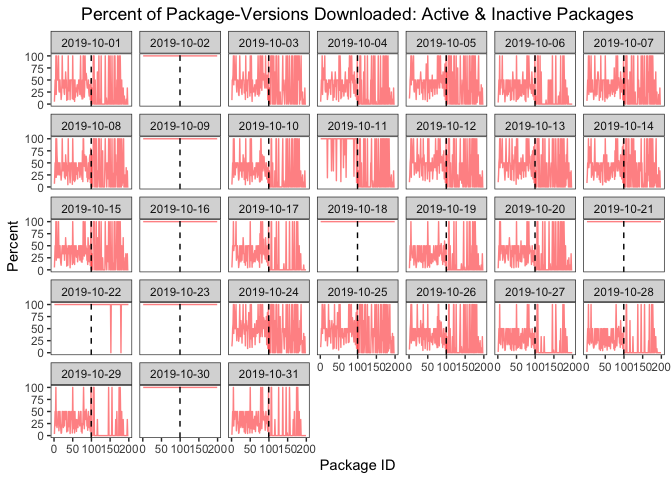
The graph below plots the percent of versions downloaded for each day in October 2019 (IDs 1-100 are active packages; IDs 101-200 are inactive packages). On the five Wednesdays (+ 3 additional days), there’s a horizontal line at 100% that indicates that all versions of the packages in the sample were downloaded.5
Figure 13 Percent of Package-Versions Downloaded for 100 Active & 100 Inactive Packages: October 2019
Solutions
To minimize this bias, we could filter out “small” downloads and past versions. Filtering out 500 B downloads is simple and straightforward (packageRank() and packageLog() already include this functionality). My understanding is that there may be plans to do this in cranlogs as well. Filtering out the other “small” downloads is a bit more involved because you’d need the size of a “valid” download. Filtering out previous versions is more complicated. You’d not only need to know the current version, you’d probably also want a way to discount rather than to simply exclude previous version(s). This is especially true when a package update occurs.
Significance
Should you be worried about this inflationary bias? In general, I think the answer is yes. For most users, the goal is to estimate interest in R packages, not to estimate traffic to CRAN. To that end, “cleaner” data, which adjusts download counts to exclude “invalid” log entries should be welcome.
That said, how much you should worry depends on what you’re trying to do and which package you’re interested in. The bias works in variable, unequal fashion. It’s a function of a package’s “popularity” (i.e, the number of “valid” downloads) and the number of prior versions. A package with more “real” downloads will be less affected than one with fewer “real” downloads because the bias gets diluted (typically, “real” interest is greater than “artificial” interest). A package with more versions will be more affected because, if CRAN in its entirety is being downloaded, a package with more versions will record more downloads than one with fewer versions.
Popularity
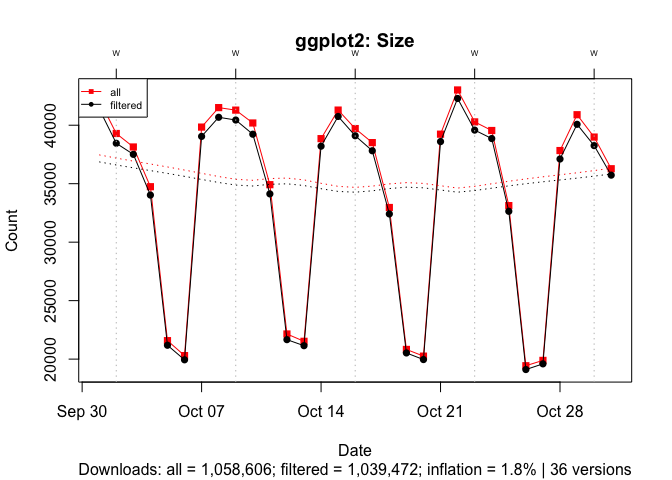
To illustrate the effect of popularity, I compare ggplot2 and cholera for October 2019. With one million plus downloads, ~500 B entries inflate the download count for ggplot2 by 2%:
Figure 14 Effect of ~500 B Downloads on Download Counts on a Popular Package: October 2019
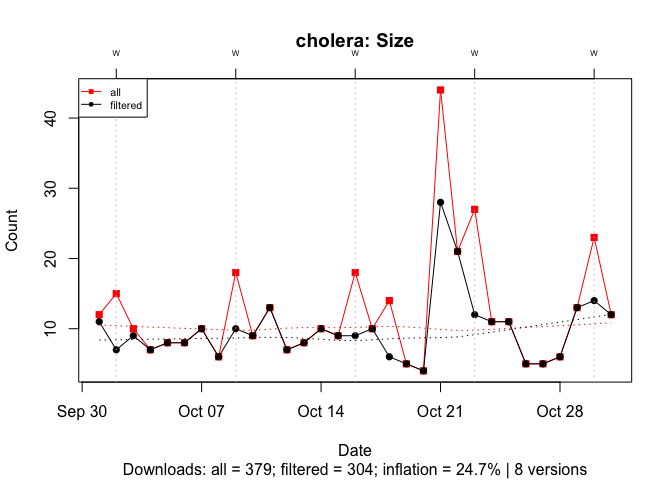
With under 400 downloads, ~500 B entries inflate the download count for cholera by 25%:
Figure 15 Effect of ~500 B Downloads on Download Counts on a Less Popular Package: October 2019
Number of versions
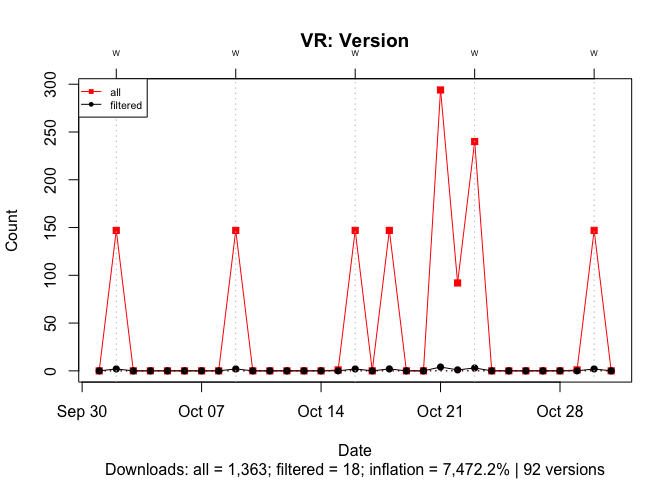
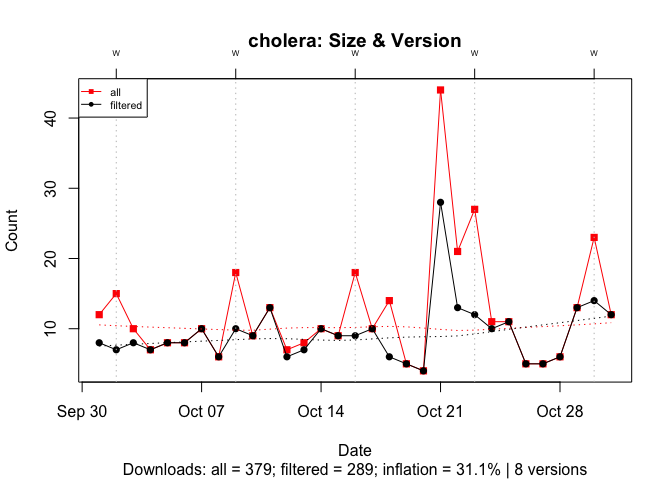
To illustrate the effect of the number of versions, I compare cholera, an active package with 8 versions, and ‘VR’, an inactive package last updated in 2009, with 92 versions. In both cases, I filter out all downloads except for those of the most recent version.
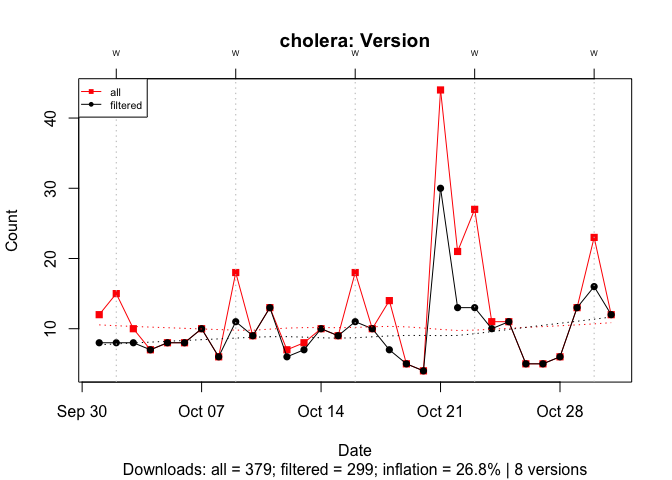
With cholera, past versions inflate the download count by 27%:
Figure 16 Effect of the Number of Prior Versions on Download Counts for a Package with Few Versions: October 2019
With ‘VR’, past version inflate the download count by 7,500%:
Figure 17 Effect of the Number of Past Versions on Download Counts for a Package with Many Versions: October 2019
Popularity & number of versions
To illustrate the joint effect of both ~500 B downloads and previous versions, I again use cholera. Here, we see that the joint effect of both biases inflate the download count by 31%:
Figure 18 Effect of ~500 B Downloads and Number of Past Versions on Download Counts: October 2019
OLS estimate
Even though the bias is pretty mechanical and deterministic, to show that examples above are not idiosyncratic, I conclude with a back-of-the-envelope estimate of the joint, simultaneous effect of popularity (unfiltered downloads) and version count (total number of versions) on total bias (the percent change in download counts after filtering out ~500 B download and prior versions).
I use the above sample of 100 active and 100 inactive packages as the data. I fit an ordinary least squares (OLS) linear model using the base 10 logarithm for the three variables. To control for interaction between popularity and number of versions (i.e., popular packages tend to have many version; packages with many version tend to attract more downloads), I include a multiplicative term between the two variables. The results are below:
Call:
lm(formula = bias ~ popularity + versions + popularity * versions,
data = p.data)
Residuals:
Min 1Q Median 3Q Max
-0.50028 -0.12810 -0.03428 0.08074 1.09940
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.99344 0.04769 62.768 <2e-16 ***
popularity -0.92101 0.02471 -37.280 <2e-16 ***
versions 0.98727 0.07625 12.948 <2e-16 ***
popularity:versions 0.05918 0.03356 1.763 0.0794 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.2188 on 195 degrees of freedom
Multiple R-squared: 0.9567, Adjusted R-squared: 0.956
F-statistic: 1435 on 3 and 195 DF, p-value: < 2.2e-16
The hope is that I at least get the signs right. That is, the signs of the coefficients in the fitted model (the “Estimate” column in the table above) should match the effects described above: 1) a negative sign for “popularity”, implying that greater popularity is associated with lower bias, and 2) a positive sign for “versions”, implying that a greater number of versions is associated with higher bias. For what it’s worth, the coefficients and the model itself are statistically significant at conventional levels (large t-values and small p-scores for the former; large F-statistic with a small p-score for the latter).
Conclusions
This post introduces some of the functions and features of packageRank. The aim of the package is to put package download counts into context using visualization and rank percentiles. The post also describes a systematic, positive bias that affects download counts and offers some ideas about how to minimize its effect.
The package is a work-in-progress. Please submit questions, suggestions, feature requests and problems to the comments section below or to the package’s GitHub Issues. Insights about “small” downloads are particularly welcome.
We are proud to announce that the R Consortium has awarded RECON a grant for $23,300 to develop the RECON COVID-19 challenge, a project aiming to centralise, organise and manage needs for analytics resources in R to support the response to COVID-19 worldwide.
These resources will permit to expand our initial preliminary collection of github issues to create a user-friendly web platform gathering R tasks reflecting needs from different projects and groups, and facilitate contributions from the wider R programming community.
We are looking for two consultants (see ‘We need you!’ section below), including:
a project manager to drive the project forward
a web developer to create the website
The RECON COVID-19 challenge in a nutshell
The RECON COVID-19 challenge aims to bring together the infectious disease modelling, epidemiology and R communities to improve analytics resources for the COVID-19 response via a website which will provide a platform to centralise, curate and update R development tasks relevant to the COVID-19 response. Similar to the Open Street Map Tasking Manager (tasks.hotosm.org), this platform will allow potential contributors to quickly identify outstanding tasks submitted by groups involved in the response to COVID-19 and ensure that developments follow the highest scientific and technical standards.
While this project is aimed at leveraging R tools for helping to respond to COVID-19, we expect that it will lead to long-lasting developments of partnerships between the R and epidemiological communities, and that the resources developed will become key assets for supporting outbreak responses well beyond this pandemic.
We are urgently looking for two consultants to get this project started. These two positions funded by the R Consortium include (click links for job descriptions):
The first COVID-19 Data Forum, co-sponsored by the Stanford Data Science Institute and the R Consortium, was held May 14, 2020. The forum used Zoom as a way to connect remote specialists, present information, and conduct a Q&A session so that participants could ask questions and give opinions.
UPDATED – Full video recording here
Close to 200 people attended, watching a range of experts cover a level of detail around COVID-19 that is not available through newspapers, and asking questions covering science and policy.
From the COVID-19 Data Forum site:
The COVID-19 pandemic has challenged science and society to an unprecedented degree. Human lives and the future of our society depend on the response. That response, in turn, depends critically on data. This data must be as complete and accurate as possible; easily and flexibly accessible, and equipped to communicate effectively with decision-makers and the public.
The COVID-19 Data Forum is a project to bring together those involved with relevant data in a series of multidisciplinary online meetings discussing current resources, needed enhancements, and the potential for co-operative efforts.
Speakers (full slides for each presentation available soon)
Orhun Aydin, Researcher and Product Engineer, ESRI
Ryan Hafen, data scientist consultant with Preva Group, and adjunct assistant professor, Purdue University
Alison L. Hill, Research Fellow and independent principal investigator at Harvard’s Program for Evolutionary Dynamics.
Noam Ross, Senior Research Scientist, EcoHealth Alliance
The Stanford Data Science Institute, which aims to give Stanford faculty and students the tools, skills and understanding they need to do cutting-edge research, is joining with the R Consortium to build the COVID-19 Data Forum series.
The COVID-19 Data Forum series is an ongoing set of online meetings that connect multidisciplinary topic experts to focus on data-related aspects of the COVID-19 pandemic modeling process such as data access and sharing, essential data resources for modeling and how we can best support decision making.
The first half of the meeting is a public webinar and all are welcome to attend.
At the Linux Foundation, we have been studying robust, scalable virtual events platforms that we can not only use for our own R Consortium events, but that we could extend as a resource to the R community.
Here is the current state of our evaluation. We’ve covered 86 virtual event platforms, and come up with a list of 4 finalists. Since specific circumstances and goals for events will always vary, we expect that there will never be a one-size-fits-all solution.
The four finalists are:
inXpo Intrado
Best for large events with high budgets requiring a virtual conference experience with few compromises
vFAIRS
Best for medium to large events with smaller budgets that want to offer a 3D environment/booth experience
MeetingPlay
Best for any size event where attendee networking tools are a priority and sponsor ‘booths’ aren’t required
QiQo Chat
QiQo is best for smaller technical gatherings that don’t need all the bells and whistles of an industry event focus, a great option for developer meetings and hackathons
The good news is that for those events that can no longer safely take place in person, virtual events still offer the opportunity to connect within our communities to share valuable information and collaborate. While not as powerful as a face-to-face gathering, a variety of virtual event platforms available today offer a plethora of features that can get us as close as possible to those invaluable in-person experiences. Thanks to our community members, we’ve received suggestions for platforms and services that the events team has spent the past several weeks evaluating.
After researching a large number of possibilities over the last few weeks, the Linux Foundation has identified four virtual event platforms (and a small-scale developer meeting tool) that could serve the variety of needs within our diverse project communities. Our goal was to determine the best options that capture as much of the real-world experience as we can in a virtual environment for virtual gatherings ranging from large to small.
If you are considering a virtual alternative for your R community meetup or event, please contact us. We may be able to help!
By Rachael Dempsey, Senior Enterprise Advocate at RStudio / Greater Boston useR Organizer
Last month, the Boston useR Group held our very first virtual meetup and opened this up to anyone that was interested in joining. While I wasn’t sure what to expect at first, I was so happy with the turnout and reminded again of just how great the R community is. Everyone was so friendly and appreciative of the opportunity to meet together during this time. It was awesome to see that people joined from all over the world – not just from the Boston area. We had attendees from the Netherlands, Spain, Mexico, Chile, Canada, Ireland, and I’m sure many other places!
Our event was a virtual TidyTuesday Meetup held over Zoom, which can hold up to 100 people without having to purchase the large meeting add-on. (If you’re worried about the number of people being over this, keep in mind that often half the people that register will attend.)
This was our agenda:
5:30: Introductions to useR Meetup & TidyTuesday (Rachael Dempsey & Tom Mock)
5:35: Presentation #1 – Meghan Hall: “Good to Great: Making Custom Themes in ggplot2”
5:50: Presentation #2 – Kevin Kent: “The science of (data science) teaching and learning”
6:00: Introduction to R for Data Science Slack Channel – Jon Harmon
6:05: Breakout into groups to work on TidyTuesday dataset – groups will be open for two-hours but you can come and go as you want!
7:30: Come back together to the Main Room for an opportunity to see a few of the examples that people would like to share
If you’re thinking of keeping your monthly event and want to host it virtually, I’ve included a few tips below:
Find someone (or multiple people) to co-host with you!
Thank you, Kevin Kent and Asmae Toumi! Kevin, a member of the Boston useR Group was originally going to be the lead for our in-person TidyTuesday meetup and posted about the meetup on Twitter, where we both met our other co-host, Asmae Toumi. Asmae then introduced us to one of our presenters, Meghan Hall. Having co-hosts not only made me feel more comfortable, but gave me a chance to bounce ideas off of someone and made it much easier to market the event to different groups of people. While I often share events on LinkedIn, Kevin and Asmae have a much bigger presence on Twitter. Aside from your own meetup group and social media, another helpful place to find potential co-hosts may be on the events thread of community.rstudio.com. Instead of co-hosting, you could also just ask people if they would be willing to volunteer to help at the meetup. Thank you to Carl Howe, Jon Harmon, Josiah Parry, Meghan Hall, Priyanka Gagneja, and Tom Mock for your support. If I can help you with finding volunteers, please don’t hesitate to reach out on LinkedIn.
Have a practice session on Zoom!
The day before the event we held a practice session on Zoom to work out a few of the kinks. As we were hosting a TidyTuesday meetup, we wanted to be able to meet in smaller groups too, as we would if we were in-person. I had never used Zoom breakout rooms before and wanted to test this out first. After the initial presentations, we broke out into 7 smaller groups. These groups worked well to help facilitate conversation among attendees. During the test, we confirmed that you can move people from different breakout groups if needed. This was helpful for keeping the groups even as some attendees had to leave before the end of the event.
Have a Slack Channel or a way for people to chat if they have questions
During the meetup, we used the R for Data Science Online Learning Community Slack Channel as a venue to ask questions and share examples of what people were working on. You can join this Slack channel by going to r4ds.io/join. We used the channel, #chat-tidytuesday which you can find by using the search bar within Slack.
Accept that it won’t be perfect
You can practice and plan how you want things to go, but I think it’s helpful to recognize that this is the first time doing this and it’s okay if things aren’t perfect. For example, we were going to create separate breakout groups based on people’s interests and have everyone use a Google doc to indicate this at the start. While it was good in theory, we determined this would be a bit too hard to manage and complicate things so I just automatically split people up into the 7 different groups. It wasn’t perfect, but it worked!
Think about Zoom best practices
This came up in discussion during our practice call and I think we’ve all seen recently that there can be a few bad-actors out there trying to ruin open meetings. @alexlmiller shared a few tips on Twitter that I’d like to cross post here as well.
You can start with the Main Settings on your Zoom account and do the following:
1) Disable “Join Before Host”
2) Give yourself some moderation help by enabling “Co-Host” – this lets you assign the same host controls to another person in the call
3) Change “Screen sharing” to “Host Only”
4) Disable “File Transfer”
5) Disable “Allow Removed Participants to Rejoin”
And also to make the overall experience a little nicer:
1) Disable “Play sounds when participants join or leave”
2) Enable “Mute participants upon entry”
3) Turn on “Host Video” and “Participants Vide” (if you want that)
One more thing, if you want to split meeting participants into separate, smaller rooms you have to enable “Breakout Rooms”.
Market your event on social media
Once your event is posted to meetup, share it with others through multiple channels. Maybe that’s a mix of your internal Slack channel, Twitter, your LinkedIn page and/or the “R Project Group” on LinkedIn …or wherever you prefer to connect with people online. Keep in mind that this could be a different audience than your usual meetups because it’s now accessible to people all over the world. Ask a few people to share your post as well so that you can leverage their network as well.
Have fun!
Reflecting back on our meetup, some of us found that with the use of Zoom breakout groups and a Slack channel our event was surprisingly more interactive than our actual in-person meetups. It was also an awesome opportunity to do something social and get together with others from the community during this crazy time. If you have any tips from your own experiences, please let me know and don’t hesitate to reach out if I can assist in any way. Hope this helps!
Esri, international supplier of geographic information system software, web GIS and geodatabase management applications, is providing a comprehensive set of resources for researchers and others mapping the spread of the coronavirus 2019 (COVID-19) pandemic.
From Esri: “As the situation surrounding coronavirus disease 2019 (COVID-19) continues to evolve, Esri is supporting our users and the community at large with location intelligence, geographic information system (GIS) and mapping software, services, and materials that people are using to help monitor, manage, and communicate the impact of the outbreak. Use and share these resources to help your community or organization respond effectively.”
The site provides
GIS Help
Access GIS Resources: COVID-19 GIS Hub
View global maps and dashboards
Get insights – View reliable, up-to-date content related to COVID-19 from trusted sources.
From Esri: As global communities and businesses seek to respond to the COVID-19 pandemic, you can take these five proactive steps to create an instant picture of your organization’s risk areas and response capacity.
Step 1
Map the cases
Map confirmed and active cases, fatalities, and recoveries cases to identify where COVID-19 infections exist and have occurred.
Step 2
Map the spread
Time-enabled maps can reveal how infections spread over time and where you may want to target interventions.
Step 3
Map vulnerable populations
COVID-19 disproportionally impacts certain demographics such as the elderly and those with underlying health conditions. Mapping social vulnerability, age, and other factors helps you monitor the most at-risk groups and regions.
Step 4
Map your capacity
Map facilities, employees or citizens, medical resources, equipment, goods, and services to understand and respond to current and potential impacts of COVID-19.
Step 5
Communicate with maps
Use interactive web maps, dashboard apps, and story maps to help rapidly communicate your situation.