

This blog is contributed by Mark Hornick, Senior Director, Oracle Machine Learning. Oracle is an R Consortium member.
Hey R users! You rely on R as a powerful language and environment for statistical analysis, data science, and machine learning. You can use R with a database to analyze and manipulate data. R provides various packages and tools for working with databases, allowing you to connect to a database, retrieve data, perform analyses, and even write data back to the database.
Many of you also work with data in—or extracted from—Oracle databases. As data volumes increase, moving data, scaling to those volumes, and deploying R-based solutions in enterprise environments complicates your life, but Oracle Machine Learning for R can simplify it!
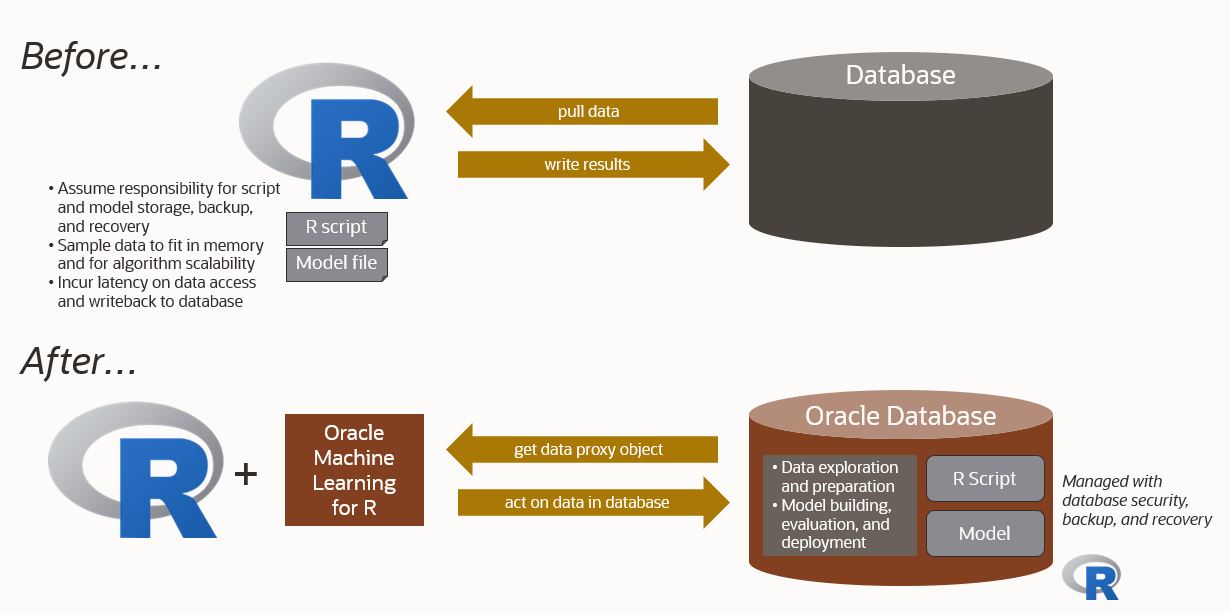
Oracle Machine Learning for R 2.0
With OML4R 2.0, we’ve expanded the set of built-in machine learning algorithms you can use from R with Oracle Database 19c and 21c. Now you also have in-database XGBoost on 21c and Neural Networks, Random Forests, and Exponential Smoothing on 19c and above. In-database algorithms allow you to build models and score data at scale without data movement.
In-database algorithms can now give you explanatory prediction details through the R interface – just like in the SQL and Python APIs. Prediction details allow you to see which predictors contribute most to individual predictions. Simply specify the number of top predictors you want and get their names, values, and weights.
> IRIS <- ore.create(iris, table='IRIS') # create table from data.frame, return proxy object
> MOD <- ore.odmRF(Species~., IRIS) # build random forest model, return model proxy object
> summary(MOD) # display model summary details
Call:
ore.odmRF(formula = Species ~ ., data = IRIS)
Settings:
valueclas.max.sup.bins 32
clas.weights.balanced OFF
odms.details odms.enable
odms.missing.value.treatment odms.missing.value.auto
odms.random.seed 0
odms.sampling odms.sampling.disable
prep.auto ON
rfor.num.trees 20
rfor.sampling.ratio .5
impurity.metric impurity.gini
term.max.depth 16
term.minpct.node .05
term.minpct.split .1
term.minrec.node 10
term.minrec.split 20Importance:
ATTRIBUTE_NAME ATTRIBUTE_SUBNAME ATTRIBUTE_IMPORTANCE
1 Petal.Length <NA> 0.65925265
2 Petal.Width <NA> 0.68436552
3 Sepal.Length <NA> 0.19704161
4 Sepal.Width <NA> 0.09617351
> RESULT <- predict(MOD, IRIS, topN.attrs=3) # generate predictions w/details, return proxy object
> head(RESULT,3) # view result
PREDICTION NAME_1 VALUE_1 WEIGHT_1 NAME_2 VALUE_2 WEIGHT_2 NAME_3 VALUE_3 WEIGHT_3
1 setosa Petal.Length 1.4 6.717 Petal.Width .200 5.932 Sepal.Length 5.1 .446
2 setosa Petal.Length 1.4 6.717 Petal.Width .200 5.932 Sepal.Length 4.9 .446
3 setosa Petal.Length 1.3 6.717 Petal.Width 200 5.932 Sepal.Length 4.7 .446Figure 1: Code to build an in-database Random Forest model using a table proxy object and use it for predictions
With datastores, you can store, retrieve, and manage R and OML4R objects in the database. To simplify object management, you can also easily rename existing datastores and all their contained objects. And you can conveniently drop batches of datastore entries based on name patterns. The same holds with the R script repository for managing R functions – load and drop scripts in bulk by name pattern.
> x <- stats::runif(20) # create example R objects
> y <- list(a = 1, b = TRUE, c = 'value')
> z <- ore.push(x) # temporary object in the database and return proxy object
> ore.save(x, y, z, name='myDatastore', # save objects to datastore 'myDatastore' in user's schema
description = 'my first datastore')
> ds <- ore.datastore() # list information about datastores in user's schema

> ore.move(name='myDatastore', newname='myNewDatastore') #rename a datastore
> ore.move(name='myNewDatastore', #rename objects within a datastore
object.names=c('x', 'y'),
object.newnames=c('x.new', 'y.new'))
> ore.datastoreSummary(name='myNewDatastore') # display datastore content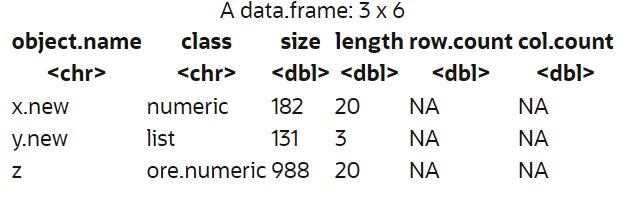
Figure 2: Code illustrating datastore functionality to store and manage R objects in the database
Some background
OML4R lets you tap into the power of Oracle Database for faster, scalable data exploration, transformation, and analysis using familiar R code. You can run parallelized in-database ML algorithms for modeling and inference without moving data around. And you can store R objects and user-defined functions right in the database for easy sharing and hand-off to application developers. You can even run R code from SQL queries and, on Autonomous Database, REST endpoints. OML4R now uses Oracle R Distribution 4.0.5 based on R 4.0.5.
Last December, as part of the R Consortium’s R/Database webinars, we presented Using R at Scale on Database Data. We highlighted the release of OML4R for Oracle Autonomous Database through the built-in notebook environment. But now you can use the same client package to connect to Autonomous Database, Oracle Database, and Oracle Base Database Service, too.

Getting started
Getting started is easy. Download and install the latest OML4R client package in your R environment and use your favorite IDE. If you’re working with Oracle Autonomous Database, you’re good to go. If you’re using Oracle Database or Oracle Base Database Service, install the OML4R server components as well. Links are below!
Get OML4R 2.0 here for use with Oracle Database and Autonomous Database and try OML4R on your data today. We think you’ll like it!
For more information
- Online Workshop: Introduction to Oracle Machine Learning for R on Oracle Database
- Online Workshop: Oracle Machine Learning Fundamentals on Oracle Autonomous Database Lab 4 on OML4R
- Blog: Oracle Machine Learning for R v2.0 now available for Oracle Database
- Blog: OML4R for Autonomous Database now available for Oracle Autonomous Database
- Documentation: Oracle Machine Learning for R
- Documentation: Oracle Machine Learning for R API Reference
- Download: Oracle Machine Learning for R
- Download: Oracle R Distribution